Logarithmic Buckets: A Technically Superior Matching Engine

The logarithmic buckets data structure introduced in Morpho’s AaveV3 Optimizer improves matching outcomes by optimizing efficiency, gas usage, and fairness.

Introduction
Morpho’s AaveV3 Optimizer is designed to be the most secure and efficient protocol for supplying and borrowing ETH and leveraging LSTs as collateral. The new and technically superior matching engine features a new data structure called logarithmic buckets which improves on the Heap and Double Linked Lists (DLL) used in AaveV2 and Compound V2 optimizers.
The Heap and DLL are traditional data structures that although efficient, can result in suboptimal matching outcomes, especially when dealing with varying liquidity amounts. This is where the logarithmic buckets data structure comes into play, offering a novel and fairer approach designed to maximize both the volume and number of users matched.
Logarithmic Buckets
The logarithmic buckets data structure allows the matching engine to sort users into multiple buckets, with each bucket accommodating positions within a specific volume range and prioritizes matching users within each bucket, although it is still possible for them to be paired with someone outside of it.
Gone are the times when smaller users would be waiting forever to be matched even when there are plenty of transactions of similar size happening.
But how exactly do log buckets differ from the Heap and DLL used in AaveV2 and CompoundV2 optimizers?
Imagine the following scenario when using a simple DLL. One user first supplies 100 ETH, and ten more supply 10 ETH each. Then ten borrowers arrive, all borrowing 10 ETH. They will get matched with the first supplier (100 ETH) because they have the largest supplied volume. If another borrower wants to borrow 100 ETH, he will loop through all the ten remaining suppliers on the pool, possibly only matching a few because of the gas limit.
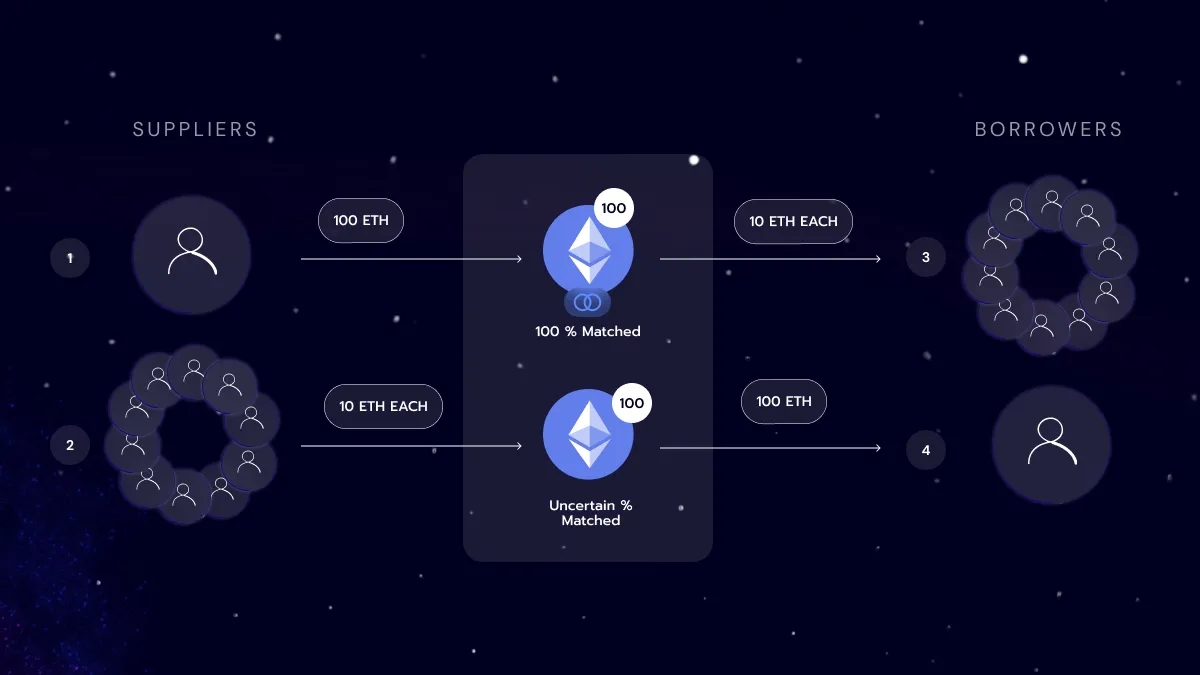
Now the scenario with logarithmic buckets, users are sorted by their amount of liquidity. When the ten borrowers come to Morpho to borrow 10 ETH each, they will get matched with the ten users supplying 10 ETH. While the user borrowing 100 ETH with be matched with the person supplying 100 ETH. Noting that this is a simplification of how it works in practice.
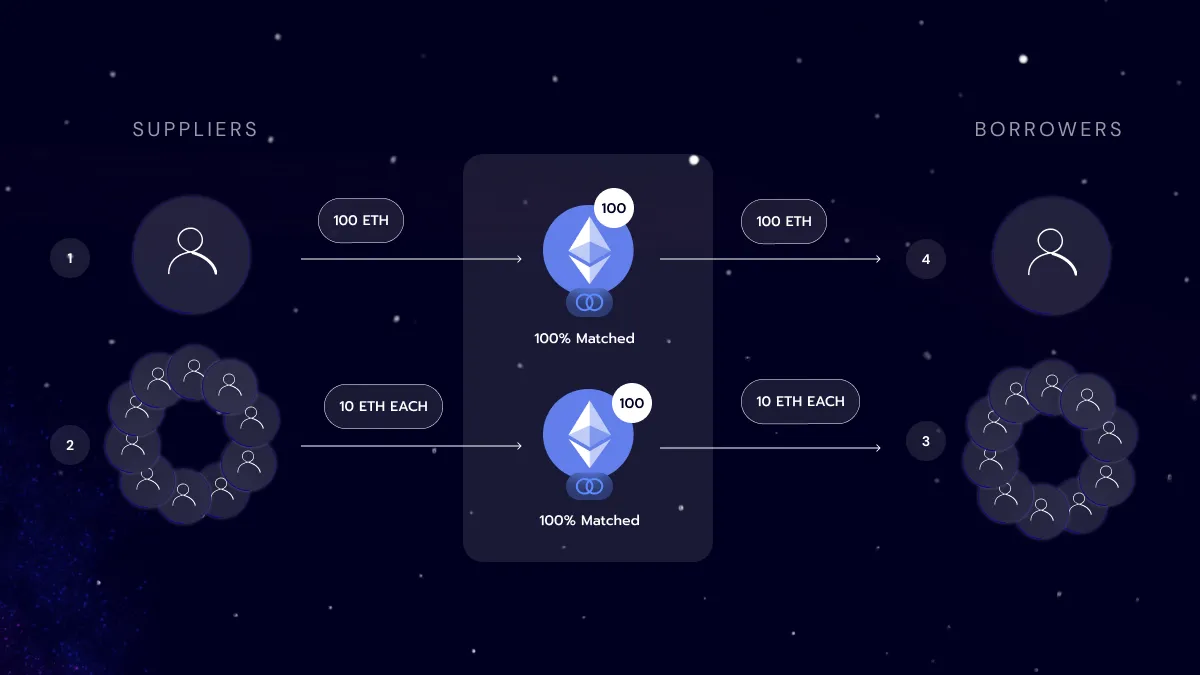
You will notice this solution ensures that most of the matching can be done in a single interaction, therefore improving gas efficiency.
Interested in the implementation? See the code code here.
Improving Efficiency, Gas Usage, and Fairness
The logarithmic buckets data structure seeks to improve three fundamental aspects of Morpho’s matching system: efficiency, gas usage, and fairness.
- Efficiency of Volume Matched: In contrast to DLL or the Heap, where a single user with the largest volume can dominate matches, the buckets categorize providers according to their liquidity sizes. As described in the earlier example, when users arrive, they are matched with users from the same bucket, resulting increasing the amount of volume matched.
- Gas Usage Optimization: Gas efficiency is a critical concern in protocols built on Ethereum. The logarithmic buckets data optimizes gas usage by leveraging the inherent properties and employing constant gas operations — the data structure ensures that all operations perform at constant time complexity. This gas efficiency further enhances the overall user experience and reduces costs associated with matching transactions.
- Promoting Fairness: Logarithmic buckets also tackle the issue of fairness in liquidity matching. In many cases, users have remained unmatched for extended periods, even when there are numerous transactions of similar sizes occurring. The logarithmic buckets data structure mitigates this problem by actively sorting suppliers and borrowers based on their liquidity sizes, eliminating bias towards large users and promoting a more equitable liquidity matching.
Conclusion
The logarithmic buckets data structure introduced in Morpho’s AaveV3 Optimizer improves matching outcomes by optimizing efficiency, gas usage, and fairness. With its ability to match liquidity providers and borrowers based on similar liquidity sizes, this new data structure offers a more efficient and equitable matching, leading to a higher percentage of total matched users over time.
To experience the improved matching engine, try Morpho’s AaveV3-ETH Optimizer.